@PostMapping("/jobPosition/listJobPositionByPage")
List<MiniJobPositionVO> listJobPositionByPage(@RequestParam(value = "posName") String posName,@RequestParam(value = "jobTypeId") String jobTypeId, @RequestBody PageBean pageBean);
当调用该接口时,posName或jobTypeId传递为null时报错400 bad request,提示需要string parameter
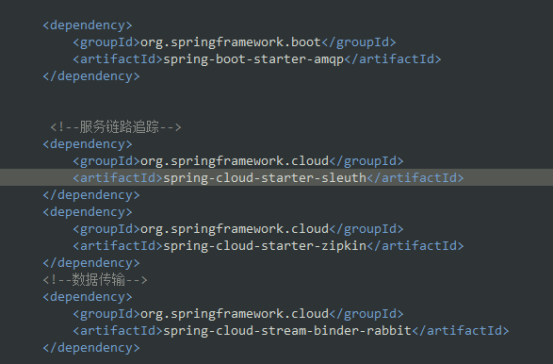
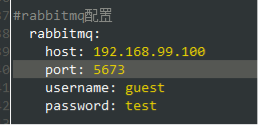
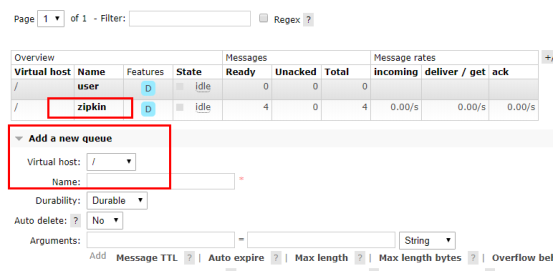
2.集成zipkin时配置正确,zipkin-server却收不到调用信息
通过HTTP使用基于Zipkin的Sleuth时,如果框架集成了rabbitmq,默认会按rabbitmq的异步方式发送调用链信息,默认的以http同步方式发送调用链信息就不会生效,注释rabbitmq配置后,发送成功。
java -jar D:\software\zipkin-server-2.10.1-exec.jar --zipkin.collector.rabbitmq.addresses=192.168.99.100:5673 --zipkin.collector.rabbitmq.username=guest --zipkin.collector.rabbitmq.password=test --zipkin.collector.rabbitmq.useSsl=false --zipkin.collector.rabbitmq.virtual-host=/ --zipkin.collector.rabbitmq.queue=zipkin
docker run -d -p 9411:9411 --env RABBIT_ADDRESSES=192.168.99.100:5673 --env RABBIT_USER=guest --env RABBIT_P
ASSWORD=test --env RABBIT_USE_SSL=false --env RABBIT_VIRTUAL_HOST=/ --env RABBIT_QUEUE=zipkin openzipkin/zipkin
|
zipkin: |
|
|
|
self-tracing: |
|
|
# Set to true to enable self-tracing. |
|
|
enabled: ${SELF_TRACING_ENABLED:false} |
|
|
# percentage to self-traces to retain |
|
|
sample-rate: ${SELF_TRACING_SAMPLE_RATE:1.0} |
|
|
# Timeout in seconds to flush self-tracing data to storage. |
|
|
message-timeout: ${SELF_TRACING_FLUSH_INTERVAL:1} |
|
|
collector: |
|
|
# percentage to traces to retain |
|
|
sample-rate: ${COLLECTOR_SAMPLE_RATE:1.0} |
|
|
http: |
|
|
# Set to false to disable creation of spans via HTTP collector API |
|
|
enabled: ${HTTP_COLLECTOR_ENABLED:true} |
|
|
kafka: |
|
|
# Kafka bootstrap broker list, comma-separated host:port values. Setting this activates the |
|
|
# Kafka 0.10+ collector. |
|
|
bootstrap-servers: ${KAFKA_BOOTSTRAP_SERVERS:} |
|
|
# Name of topic to poll for spans |
|
|
topic: ${KAFKA_TOPIC:zipkin} |
|
|
# Consumer group this process is consuming on behalf of. |
|
|
group-id: ${KAFKA_GROUP_ID:zipkin} |
|
|
# Count of consumer threads consuming the topic |
|
|
streams: ${KAFKA_STREAMS:1} |
|
|
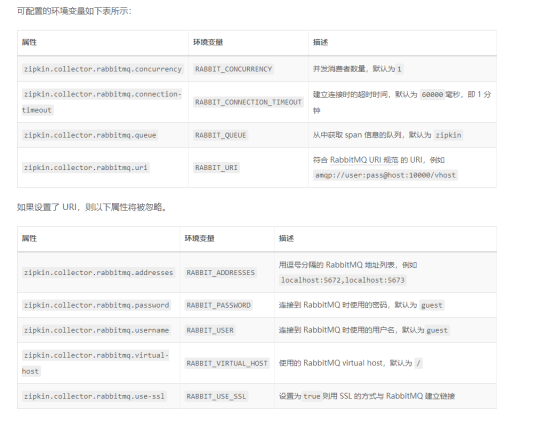
rabbitmq: |
|
|
# RabbitMQ server address list (comma-separated list of host:port) |
|
|
addresses: ${RABBIT_ADDRESSES:} |
|
|
concurrency: ${RABBIT_CONCURRENCY:1} |
|
|
# TCP connection timeout in milliseconds |
|
|
connection-timeout: ${RABBIT_CONNECTION_TIMEOUT:60000} |
|
|
password: ${RABBIT_PASSWORD:guest} |
|
|
queue: ${RABBIT_QUEUE:zipkin} |
|
|
username: ${RABBIT_USER:guest} |
|
|
virtual-host: ${RABBIT_VIRTUAL_HOST:/} |
|
|
useSsl: ${RABBIT_USE_SSL:false} |
|
|
uri: ${RABBIT_URI:} |
|
|
query: |
|
|
enabled: ${QUERY_ENABLED:true} |
|
|
# 1 day in millis |
|
|
lookback: ${QUERY_LOOKBACK:86400000} |
|
|
# The Cache-Control max-age (seconds) for /api/v2/services and /api/v2/spans |
|
|
names-max-age: 300 |
|
|
# CORS allowed-origins. |
|
|
allowed-origins: "*" |
|
|
|
|
|
storage: |
|
|
strict-trace-id: ${STRICT_TRACE_ID:true} |
|
|
search-enabled: ${SEARCH_ENABLED:true} |
|
|
type: ${STORAGE_TYPE:mem} |
|
|
mem: |
|
|
# Maximum number of spans to keep in memory. When exceeded, oldest traces (and their spans) will be purged. |
|
|
# A safe estimate is 1K of memory per span (each span with 2 annotations + 1 binary annotation), plus |
|
|
# 100 MB for a safety buffer. You'll need to verify in your own environment. |
|
|
# Experimentally, it works with: max-spans of 500000 with JRE argument -Xmx600m. |
|
|
max-spans: 500000 |
|
|
cassandra: |
|
|
# Comma separated list of host addresses part of Cassandra cluster. Ports default to 9042 but you can also specify a custom port with 'host:port'. |
|
|
contact-points: ${CASSANDRA_CONTACT_POINTS:localhost} |
|
|
# Name of the datacenter that will be considered "local" for latency load balancing. When unset, load-balancing is round-robin. |
|
|
local-dc: ${CASSANDRA_LOCAL_DC:} |
|
|
# Will throw an exception on startup if authentication fails. |
|
|
username: ${CASSANDRA_USERNAME:} |
|
|
password: ${CASSANDRA_PASSWORD:} |
|
|
keyspace: ${CASSANDRA_KEYSPACE:zipkin} |
|
|
# Max pooled connections per datacenter-local host. |
|
|
max-connections: ${CASSANDRA_MAX_CONNECTIONS:8} |
|
|
# Ensuring that schema exists, if enabled tries to execute script /zipkin-cassandra-core/resources/cassandra-schema-cql3.txt. |
|
|
ensure-schema: ${CASSANDRA_ENSURE_SCHEMA:true} |
|
|
# 7 days in seconds |
|
|
span-ttl: ${CASSANDRA_SPAN_TTL:604800} |
|
|
# 3 days in seconds |
|
|
index-ttl: ${CASSANDRA_INDEX_TTL:259200} |
|
|
# the maximum trace index metadata entries to cache |
|
|
index-cache-max: ${CASSANDRA_INDEX_CACHE_MAX:100000} |
|
|
# how long to cache index metadata about a trace. 1 minute in seconds |
|
|
index-cache-ttl: ${CASSANDRA_INDEX_CACHE_TTL:60} |
|
|
# how many more index rows to fetch than the user-supplied query limit |
|
|
index-fetch-multiplier: ${CASSANDRA_INDEX_FETCH_MULTIPLIER:3} |
|
|
# Using ssl for connection, rely on Keystore |
|
|
use-ssl: ${CASSANDRA_USE_SSL:false} |
|
|
cassandra3: |
|
|
# Comma separated list of host addresses part of Cassandra cluster. Ports default to 9042 but you can also specify a custom port with 'host:port'. |
|
|
contact-points: ${CASSANDRA_CONTACT_POINTS:localhost} |
|
|
# Name of the datacenter that will be considered "local" for latency load balancing. When unset, load-balancing is round-robin. |
|
|
local-dc: ${CASSANDRA_LOCAL_DC:} |
|
|
# Will throw an exception on startup if authentication fails. |
|
|
username: ${CASSANDRA_USERNAME:} |
|
|
password: ${CASSANDRA_PASSWORD:} |
|
|
keyspace: ${CASSANDRA_KEYSPACE:zipkin2} |
|
|
# Max pooled connections per datacenter-local host. |
|
|
max-connections: ${CASSANDRA_MAX_CONNECTIONS:8} |
|
|
# Ensuring that schema exists, if enabled tries to execute script /zipkin2-schema.cql |
|
|
ensure-schema: ${CASSANDRA_ENSURE_SCHEMA:true} |
|
|
# how many more index rows to fetch than the user-supplied query limit |
|
|
index-fetch-multiplier: ${CASSANDRA_INDEX_FETCH_MULTIPLIER:3} |
|
|
# Using ssl for connection, rely on Keystore |
|
|
use-ssl: ${CASSANDRA_USE_SSL:false} |
|
|
elasticsearch: |
|
|
# host is left unset intentionally, to defer the decision |
|
|
hosts: ${ES_HOSTS:} |
|
|
pipeline: ${ES_PIPELINE:} |
|
|
max-requests: ${ES_MAX_REQUESTS:64} |
|
|
timeout: ${ES_TIMEOUT:10000} |
|
|
index: ${ES_INDEX:zipkin} |
|
|
date-separator: ${ES_DATE_SEPARATOR:-} |
|
|
index-shards: ${ES_INDEX_SHARDS:5} |
|
|
index-replicas: ${ES_INDEX_REPLICAS:1} |
|
|
username: ${ES_USERNAME:} |
|
|
password: ${ES_PASSWORD:} |
|
|
http-logging: ${ES_HTTP_LOGGING:} |
|
|
legacy-reads-enabled: ${ES_LEGACY_READS_ENABLED:true} |
|
|
mysql: |
|
|
host: ${MYSQL_HOST:localhost} |
|
|
port: ${MYSQL_TCP_PORT:3306} |
|
|
username: ${MYSQL_USER:} |
|
|
password: ${MYSQL_PASS:} |
|
|
db: ${MYSQL_DB:zipkin} |
|
|
max-active: ${MYSQL_MAX_CONNECTIONS:10} |
|
|
use-ssl: ${MYSQL_USE_SSL:false} |
|
|
ui: |
|
|
enabled: ${QUERY_ENABLED:true} |
|
|
## Values below here are mapped to ZipkinUiProperties, served as /config.json |
|
|
# Default limit for Find Traces |
|
|
query-limit: 10 |
|
|
# The value here becomes a label in the top-right corner |
|
|
environment: |
|
|
# Default duration to look back when finding traces. |
|
|
# Affects the "Start time" element in the UI. 1 hour in millis |
|
|
default-lookback: 3600000 |
|
|
# When false, disables the "find a trace" screen |
|
|
search-enabled: ${SEARCH_ENABLED:true} |
|
|
# Which sites this Zipkin UI covers. Regex syntax. (e.g. http:\/\/example.com\/.*) |
|
|
# Multiple sites can be specified, e.g. |
|
|
# - .*example1.com |
|
|
# - .*example2.com |
|
|
# Default is "match all websites" |
|
|
instrumented: .* |
|
|
# URL placed into the <base> tag in the HTML |
|
|
base-path: /zipkin |
|
|
|
|
|
server: |
|
|
port: ${QUERY_PORT:9411} |
|
|
use-forward-headers: true |
|
|
compression: |
|
|
enabled: true |
|
|
# compresses any response over min-response-size (default is 2KiB) |
|
|
# Includes dynamic json content and large static assets from zipkin-ui |
|
|
mime-types: application/json,application/javascript,text/css,image/svg |
|
|
|
|
|
spring: |
|
|
jmx: |
|
|
# reduce startup time by excluding unexposed JMX service |
|
|
enabled: false |
|
|
mvc: |
|
|
favicon: |
|
|
# zipkin has its own favicon |
|
|
enabled: false |
|
|
autoconfigure: |
|
|
exclude: |
|
|
# otherwise we might initialize even when not needed (ex when storage type is cassandra) |
|
|
- org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration |
|
|
info: |
|
|
zipkin: |
|
|
version: "@project.version@" |
|
|
|
|
|
logging: |
|
|
pattern: |
|
|
level: "%clr(%5p) %clr([%X{traceId}/%X{spanId}]){yellow}" |
|
|
level: |
|
|
# Silence Invalid method name: '__can__finagle__trace__v3__' |
|
|
com.facebook.swift.service.ThriftServiceProcessor: 'OFF' |
|
|
# # investigate /api/v2/dependencies |
|
|
# zipkin2.internal.DependencyLinker: 'DEBUG' |
|
|
# # log cassandra queries (DEBUG is without values) |
|
|
# com.datastax.driver.core.QueryLogger: 'TRACE' |
|
|
# # log cassandra trace propagation |
|
|
# com.datastax.driver.core.Message: 'TRACE' |
|
|
# # log reason behind http collector dropped messages |
|
|
# zipkin2.server.ZipkinHttpCollector: 'DEBUG' |
|
|
# zipkin2.collector.kafka.KafkaCollector: 'DEBUG' |
|
|
# zipkin2.collector.kafka08.KafkaCollector: 'DEBUG' |
|
|
# zipkin2.collector.rabbitmq.RabbitMQCollector: 'DEBUG' |
|
|
# zipkin2.collector.scribe.ScribeCollector: 'DEBUG' |
|
|
|
|
|
management: |
|
|
endpoints: |
|
|
web: |
|
|
exposure: |
|
|
include: '*' |
|
|
endpoint: |
|
|
health: |
|
|
show-details: always |
|
|
# Disabling auto time http requests since it is added in Undertow HttpHandler in Zipkin autoconfigure |
|
|
# Prometheus module. In Zipkin we use different naming for the http requests duration |
|
|
metrics: |
|
|
web: |
|
|
server: |
|
|
auto-time-requests: false |