============================原理===================
//RestTemplate restTemplate = new RestTemplate();
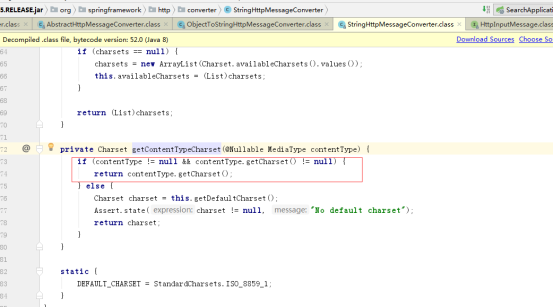
// 当返回的response-header的content-type属性有charset值时,
// restTemplate的 StringHttpMessageConverter会读取该charset值,并使用该值进行
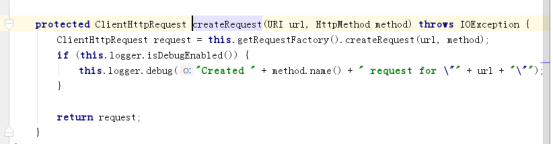
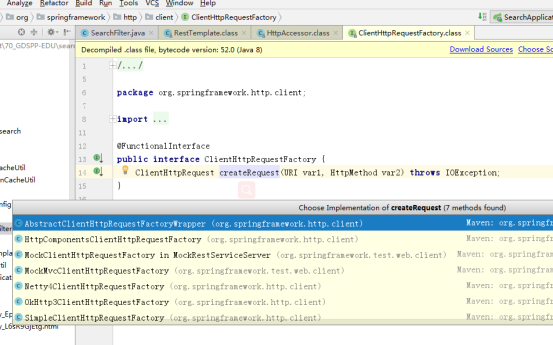
通过源码可以发现restTemplate底层默认使用了HttpURLConnection,可以支持其他多种http客户端,如httpclient、okhttp等,通过工厂方法模式创建请求:
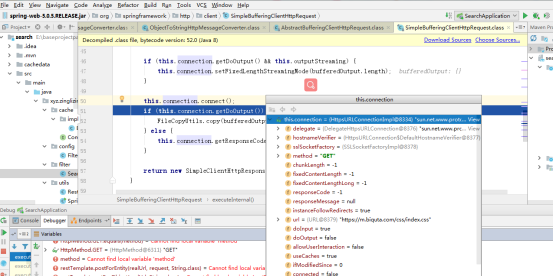
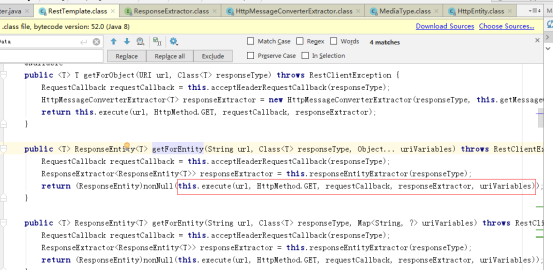
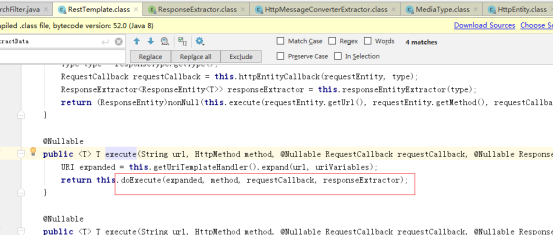
执行请求,调用ResponseExtractor responseExtractor.extractData()对相应结果进行数据提取
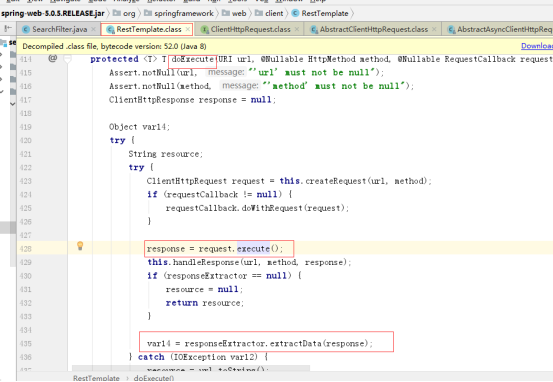
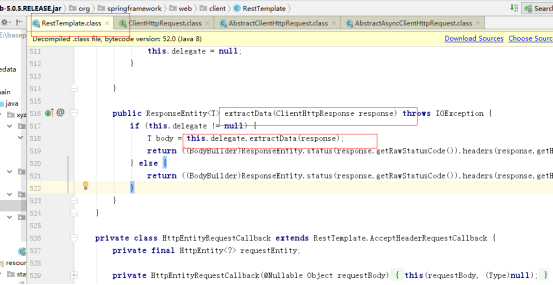
调用HttpMessageConverterExtractor this.delegate.extractData()执行抽取数据的操作
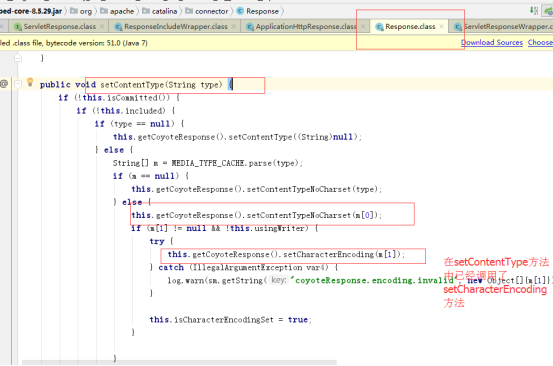
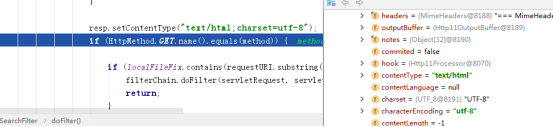
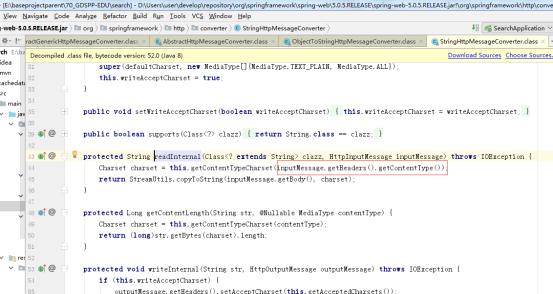
获取response-header的content-type,
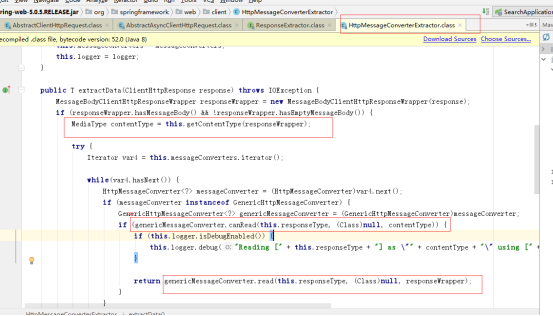
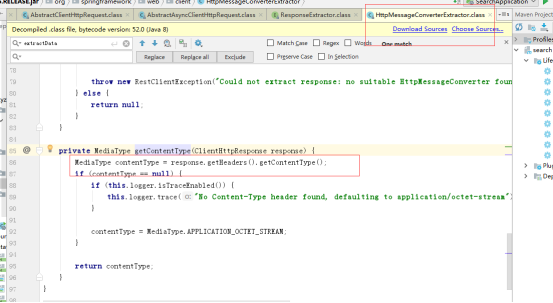
判断消息转换器对应的支持媒体类型supportMediaType是否包含该content-type
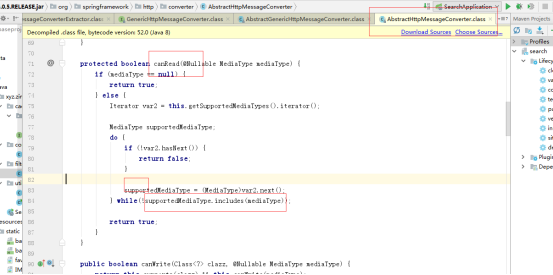
调用第一个包含该content-type的GenericHttpMessageConverter转换数据读取数据
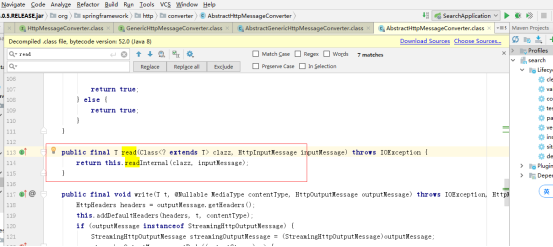
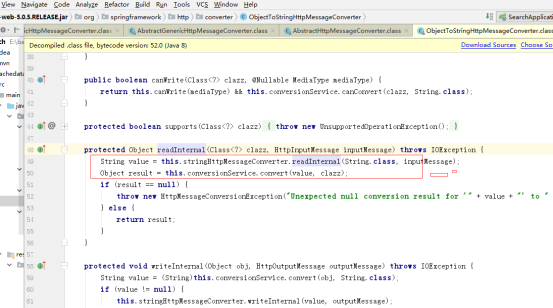
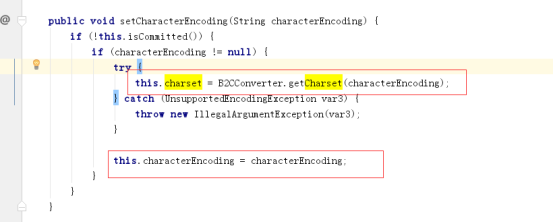
读取数据的时候会再一次获取response-header的content-type的字符集
如果该字符集存在,则使用该字符集进行 IO流 =》字符串 转换
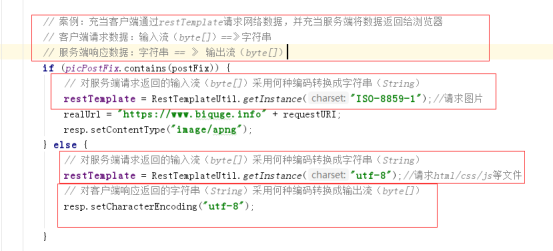
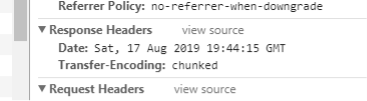
响应头中并没有content-type的header,照理说浏览器应该不知道服务端返回的输入流编码,如果和浏览器默认的编码不匹配应该会出现乱码,但是现在浏览器有编码自动识别功能,所以上面的代码没有加content-type的Header也没有问题